- Abstract
The popularity of the intellectual, addicting game, Ultimate Tic Tac Toe, is rising exponentially, yet the game lacks a sophisticated artificially intelligent computer player to challenge human players. At the Artificial Intelligence course in EPGY, I worked on a novel approach to the AI for Ultimate Tic Tac Toe. Instead of making computers act like humans, I was inspired to make computers THINK like humans by allowing them to learn from past experiences, which is the concept of case based reasoning. Human intelligence is not defined by what humans know; it is defined by “how” we know. My goal is to replicate true human intelligence through implementing case based reasoning on this game. By completing this project, I hope to expand the case based reasoning’s range of application and contribute new ways to implement case based reasoning.
2. Background on Case Based Reasoning
In order to create the most intelligent artificial system for a game, one must consider what makes the computer’s opponent, the human, a worthy adversary. Above all other human capabilities, the ability to learn from experiences makes humans the most intelligent life forms. My purpose is to replicate this behavior and thought process in a computer bot so that it will grow in intelligence after every game.
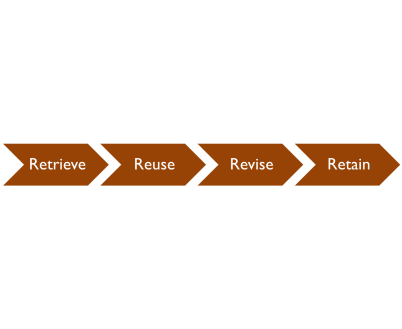
The primary process in case based reasoning is the 4 R’s: retrieve, reuse, revise, and retain. In a current situation, the computer player will first retrieve, or examine actions in similar past experiences. After accumulation of past experiences, the computer will mutate the past experience (reuse and revise) in order to make it fit in the current situation. If the action in the current situation was successful, then the action will be retained, and recorded as a successful past experiece. As this cycle iterates, a computer player will become more and more intelligent after every consecutive game it has played.
3. Application- What is Ultimate Tic Tac Toe?
Ultimate Tic Tac Toe is defined as a 3×3 Tic Tac Toe game in which each square has its own tic tac toe game.

The picture above best describes the gameboard for this game. A comprehensive guide to the rules of this game can be found in here (http://mathwithbaddrawings.com/2013/06/16/ultimate-tic-tac-toe/). The rules of the game make it very intellectual and thus, very addicting. Therefore, creating a bot with learning capabilities for such a complicated game is a novel proposition.
4. Previous Work in Case Based Reasoning
To create computer bots for the artificial intelligence Starcraft conferences, many teams implement case based reasoning so that their computer player can use tactics from its previous opponents and battles in order to succeed in its current situations. Also, corporations such as Verdande technology use case based reasoning in their products. Their data mining product, Edge Platform, uses previous problems and solutions to tackle current situations. Even though this product is used broadly across various fields, the computer can find similarities between situations of different clients and perform optimally.

5. Current AI in Ultimate Tic Tac Toe
Ultimate Tic Tac Toe applications on the web most commonly have random, unintelligent computer players. There is one on the khan academy website that uses a monte carlo search tree (MCST) to make moves. MCST evaluates every next move by simulating games that would occur after each move. Then the computer player chooses the next move that guarantees the most amount of future optimal results. This implementation allows the computer to think in advance and makes moves accordingly.

However intelligent this gameplay might seem, this does not prevent the computer player from making mistakes over and over again. If a computer player isn’t able to use case based reasoning to learn from experiences, a human player may exploit this discrepancy and be able to beat the computer player every time by making the computer make the same mistake every time. The current AI for Ultimate Tic Tac Toe doesn’t significantly challenge human players and becomes very easy to beat after exploitation.
6. Proposed Solution
I set up a localhost MySQL server in order to record each game in a table within a single database. With the JDBC driver, I am able to connect my JAVA application to the MySQL server during a game. After I access all the data from my previous games, I sort through the moves and only analyze the winner’s moves from each game. After playing the game several times, I realized that the game strategy and technique changes at different points of the game. Furthermore, human players prioritize which square to play in depending on their depth into the game. Therefore, I divide each game into three equal sections and classify each move into the section of the game that it was played in. Then, I took these three individual clusters of moves and created a probability model for each cluster. The computer player would then apply one of these models depending on the computer player’s depth into the current game. I decided to use a probability model to create a dynamic computer player because dynamic gameplay is hard to exploit since it is unpredictable. Plus, this gives the human player the feeling that it is playing against a sophisticated, human-like bot.
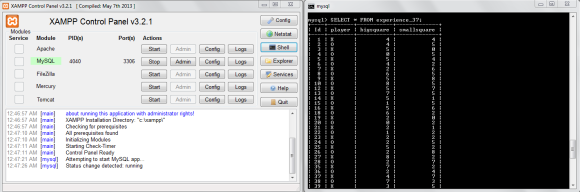
Shows the localhost MySQL server I used to save past game experiences.
7. Conclusion
The bot for my game is just like the camel in this old proverb. I, the camel owner, had given the camel all the resources and wisdom to guide it to the water, but only the camel could decide if it wanted to drink water or not. I had given the AI bot a myriad of experience and the ability to cleverly analyze, yet would my bot use the resources to play better or fail? The artificially intelligent bot was extremely bad player after playing one or two games, but after it got more and more experience under its belt, it played with more sophistication and demonstrated a greater understanding for the game. It even inherited tactics and strategies from previous players and implemented them in its future gameplay. The probability model made it impossible to exploit and an even more worthy adversary for the human player. Players for this game comment that it was much more challenging than the MCST computer player for this game.

The computer player (O) defeats one of my friends (X)
8. Future Work
I hope to implement alpha-beta pruning or MCST to the computer player so that I can create a Perfect Bot that will use both foresight and hindsight to become an extremely difficult player to beat. I am also looking forward to specify the classification of the previous games’ data, and implement markov chains in order to create smarter and more specific probability models. Above all, I hope to release a free version of this game on the Android market.
9. References
http://en.wikipedia.org/wiki/Case-based_reasoning
http://artint.info/html/ArtInt_190.html
http://www.youtube.com/watch?v=87FhSfvOiwU
http://www.verdandetechnology.com/home/products-and-services/edge-platform/
https://www.khanacademy.org/cs/in-tic-tac-toe-ception-perfect/1681243068